
本帖最后由 △@← 于 2022-4-14 11:07 编辑
数据包结构 、 各种存储或判断方式的性能测试、以及游戏更新顺序的测试
本帖还有很多不完善的地方 欢迎提供移除、修改和补充的意见 本帖有许多零碎的东西,持续不定期更新 “写写分别的特性和性能比较并写写在计算中的利用方式和一些技巧最重要的是给出你的data规范”——Xiao2 #写帖起因 我之前的数据包用data用得挺少,函数之间传参也挺少的在搞第五版数据包的时候,打算模仿类的样子来写,然后第四版的basic分成了底层和基本库两个数据包,底层用来处理各种不那么优雅的东西,然后基本库就可以写得更优雅一点了即使我在开始编写的时候心中有了大致的规范,但实际编写的过程中,随着函数的增多,数据包越来越乱,越来越不优雅,我意识到我可能需要把这些规范更加清楚地整理一下而且在写各种函数的时候由于函数允许的输入输出变多了很多,想兼顾效率和使用体验以及编辑体验以及可拓展性,,,,计分板和data(storage,entity,block)的存储和使用各有优劣,搞的我头都大了,加上@Xiao2的建议,就写了这个帖子(并进行了一些测试)然后测试越来越多。。。。
#点击目录翻页!!
#函数结构 可以去这里看一下( 函数命令系统 )
##mcf调用-if结构 MC中的if结构只能通过调用mcf来减少重复判断可以采用execute if xx 结构来进行判断可以先采用execute store 存储特定命令的返回值后再进行判断来达到更广的判别范围建议用计分板作为if控制的条件
###且(&&)与或(||) execute 命令自带且的逻辑,只需要叠加上去就行想要实现或的逻辑的话,需要放多个并排的execute if,并且保证两个条件没有交集以防被执行两次,或者用!((!a)&&(!b))也行用后者大概是这样not_found=0exe unless scb==a unless scb==brun not_found=1exe if not_found==0 run func…
###并排使用executeif 注意并排使用if的时候,if的条件在执行的函数内不应该被改变,否则可能会出现意料之外的效果建议并排使用if的时候新建一个关于if的临时计分板作为控制,而不是直接使用条件并排实现或大概是这样scb_ = scbexe if scb_== a run func..exe unless scb_ == a if scb_ ==b run func
###if else结构 If else的执行原则就是从第一个条件判断开始,一路往下进行判断,遇到符合的条件就执行并且不再判断后面的代码块,如果没有符合的条件,则执行else下的代码块为了达到效果需要创立另一个计分板用mcf写大概是这样temp = conditionfind = 0not_de =0#一般条件exe if find ==0 if temp == a runfunc Aexe if find ==0 if temp == a runfind =1#且exe if find ==0 if temp == b iftemp == c run func Bexe if find ==0 if temp == b if temp== c run find =1#或exe if find ==0 unless temp == dunless temp ==e run not_de =1exe if find ==0 if not_de ==0run func Cexe if find ==0 if not_de ==0run find =1exe if find ==0 run func ELSE
###断言方式的利用形式
参见
断言提供丰富的逻辑结构,包括
##mcf调用-循环结构 MC的所有循环结构只能通过在mcf末尾 有条件 地调用自己来达到,这是一种递归(自己调用自己) 建议所有这样的函数都在前面加上loop以方便识别比如这是一个死循环,不管以什么方式触发,一旦运行就无限递归然后循环到每tick命令上限
loop_a.mcf a += 1func a
这是一个正常点的循环,运行loop_a,b会运行100次然后结束,并输出100,所有运算都是1tick内完成的,并且中途不会运行其它任何其它mcf或进行任何其它计算(废话)
loop_a.mcf scb=0max=100func bsay scb
b.mcf scb += 1if scb <max run func b
改一下就变成了有点用处的函数,运行loop_a就能计算1加到100的值,并输出5050
loop_a.mcf scb=0max=100value=0func bsay value
b.mcf scb += 1value += scbif scb <max run func b
###列表递归 MC允许通过<路径>[num]来读取列表内的元素,但num却不能接受来自计分板或data的参数,因此在数据包中通常选择第0位读取,加上递归的方式来遍历列表
#检测列表list中uid为<scb>的项,并输出对应的name a.mcf check = <scb>data temp_list =data listexe if data temp_list[0] runfunc loop_say_name
loop_say_name.mcf uid = data temp_list[0].uidexe if uid == check run say datatemp_list[0].namedata remove temp_list[0]exe if data temp_list[0] runfunc loop_say_name
列表的方法也能用在数组上,两者在使用的时候差不多
##循环体 这是@Xiao2提出的一个概念,基本逻辑是把单tick内的循环拆分到多tick内分步执行,通常附带一个参数作为循环上限,也可以不附带参数,这样需要被调用函数主动结束循环像一个临时触发,持续一段时间的tick启动计分板key可以在任意函数的任意地方开启和关闭,甚至可以暂停一段时间然后继续运行循环体的一个重要特性是没有用到任何的递归,无循环上限的循环体和无条件的schedule循环差不多例子#当运行a的时候让玩家向前冲刺一段距离(无视方块)
#复杂一点的冲刺(输入时间速度,简单区分方块,用到了递归)
#计算x加到y,默认y>x,相差越大计算时间越久(没啥用的东西)
#砍树连锁(有很多省略,把注释取消掉就加上了循环上限)
##schedule循环 这大概是广为人知的一个循环方式(大概),函数通过schedule调用自己可以产生tick循环的效果,并且可以根据需要随时开启和终结,或者设置条件让其自己终结,产生类似循环体的效果无条件的schedule循环可以代替tick,只要从load开始就行,唯一的不同是schedule是在所有tick执行后再执行的建议无条件循环的schedule循环的mcf前面加上keep
#这是一个普通的schedule循环,作用是一直say hi
如果我要开始say hi,那么运行func keep_say_hi就能一直say hi了如果我要结束say hi,那么运行schedule clear keep_say_hi就能结束say hi了 #玩家向前冲刺一段距离(无视方块)
#砍树连锁(有很多省略)
这个比上面的循环体更为简洁
##函数:向下套娃以及_def0 在简写里面已经说过了函数的定义,函数能创建同名的文件夹与自己并列,然后这个文件夹就也是自己的一部分这里可以进行套娃,来进行大量函数的有效整理,比如可以创建一个_def0函数来定义所有需要的触发器建议调用自己同名文件夹下一级所有mcf的函数前方加上一个下划线(_),并且在后方加上分别层级的数字例如
这样,我们用一个_def0就能定义所有基本或者高级的触发器,随后只要判断简单的计分板触发对应的函数就行了
## 函数:向上套娃以及继承 复制粘贴可以在最广泛的方面达到继承的效果,但是会增大数据包以及维护的量 如果结构允许的话 先写好一个模板然后通过直接调用函数来继承是最好的(可以参考我的棋盘数据包,,) 关于函数标签,如果你没打算做前置,就不需要使用,所以这方面我的棋盘数据包滥用了函数标签呜呜呜。。。
旧贴(别看,别看,我说了别看)
###指导总纲: 面向对象思想(参考链接: 百度百科 知乎 简书 ) 本文主要提供数据包的结构以及规范的建议这些东西和本文没什么关系,但是讲得的真的不错(除了百度百科)
###类与对象 这里的模块对应的就是类,函数对应的就是类的方法 子模块放在父模块的文件夹下, MC的数据包并不完全支持继承(你要完全不考虑效率当我没说),这里对继承进行了一点点尝试 以下结构可以进行一定意义的继承,但并不完全适用于 MC ,请斟酌使用
### __import函数 模块下可以有一个__import函数,用来进行模块的继承,以及模块内函数的调用 如何理解见上面的指导总纲,每一个模块的__import函数都被所有子模块的__import函数调用,同时调用父模块的__import(如果有父模块),并且根据func_uid调用本模块的所有函数
###多重继承 __import的结构允许多重继承 仅继承一个模块的模块放进父模块的文件夹下与父模块的其它函数并列 继承多个模块的模块作为根模块放到functions下第一级 同时__init由load调用而不是父模块的__init 多重继承的func_uid通常会有冲突,需要在__import内自行决定是都调用,还是按情况进行选择 使用的临时变量可以命名为scb ##<@s>.__import func_uid或者storage temp{“<@s>.__import”:”func_name”}
###func_uid与函数 __import判断调用哪一个函数的计分板规定为scb ##import func_uid,每次使用的时候都要重新设定 func_uid对应哪一个函数名可以有以下3种方法,第一种和第二种不冲突 #函数名 将函数命名为<func_uid>_<func_name>
###多态 重写可以在__import内上一级__import的调用之前检测对应的函数号,并在之后清除计分板的值 重载同理,不过在新的函数内要if调用旧的函数,达到添加新的输入参数类型的目的 如果要筛选一般的参数的话,可以见下#数据类型判断与筛选,但碰上更复杂的就不行了,建议附带一个额外的参数来选择函数模式,启用或禁用一 部分的代码块 因此__import内[重写或重载函数的调用必须在[父函数的__import的调用之前
#数据包结构 前置教程(不是)
#观看前可以参考
#这里是简写
废话一堆
#必要性以及原因
#文件夹结构的矛盾
(2021/7/25)
#解决方案 旧贴
(发帖的时候)
(指发帖后过了好多天的,对于今天而言的,前几天)
(今天2020/12/20)
(2021/7/25)
#最大化效率 旧贴
理想的情况应该是数据包作者根据自己的数据包需要的功能选择需要启用的触发器,
数据包制作者可以根据需求定义和组合触发器然后所有的触发器经过加载后转变为计分板的被检测形式通过检测计分板来触发函数
就算同时安装了这个前置的其它数据包,基本模块定义的触发器的检测不会执行第二遍
如果命名够规范的话也能做到一部分的自定义触发器检测不会执行第二遍
若想尽可能缩减消耗的话,尽可能少用选择器才是对的而主函数部分是选择器泛滥的区域,,显然大家不可能都用同一个主函数模块但可以在自己的数据包内采用主函数模块例如有了一个as @a run xx ,其他的as @a 就不用写了,全部都放进这个函数吧(能用function就不要大规模穷举,除非看着更舒服能用计分板就尽可能使用计分板用nbt时尽可能减少路径层数,尤其是大规模穷举或递归时,可以直接加双引号把路径括起来变成一层路径(划掉),但只要不是这种情况,还是以方便理解为优先
#最大化编辑维护体验 旧贴
理想的情况应该是数据包制作者能比较方便地创建和管理自定义的触发器并且所有的函数都由定义的触发器直接或间接地触发所有文件模块化,并能迅速明白这是干什么用,怎么用的把tick/refresh这样的,load这样的,平等地看成触发器模块中被调用的与主动调用的函数能被明显区分,建一两个文件夹也好,统一为tick、load也好主动与被动取决于该函数是否打算被其它模块,或者是玩家调用主动与被动
相对于模块而言,主动函数就是tick,load以及仅被其调用的一系列本模块函数,相当于运行主体,被动则是属于该模块却被自身或其它模块调用的函数相对于玩家而言,主动函数与被动函数的意义差不多相反,用于被玩家调用的功能函数反而是主动函数,模块自动运行的函数反而是被动函数这里采用相对于模块的视角如果采用系统模块的方式,应该把所有的主动函数都放进系统模块内,系统模块内将会成为一个庞大的编辑区域,此时的系统模块和其它编程语言的main别无二致留下系统模块可以更精准地控制数据包内函数的运行顺序,Xiao2更倾向于留下main模块重点是保持一个贯穿始终的布置规则这里有几个简单的规则1.data/<自己的命名空间>/functions/<数据包空间>/...如果这样的话,s3.chessboard就是data/s3/functions/chessboard/tick.mcfunction对应s3:chessboard/tick这样的好处是自己的不同数据包放在一起的时候翻文件夹会快乐一些2.对于函数<path>/a调用的函数,如果仅它自身调用这个函数,那么就<path>/a/<待调用函数>,这样会使函数调用关系显得一目了然如果<path>/a调用的是一系列相似的函数,则可以直接建一列文件夹,运行<文件夹i>/run3.如果有一堆模块,那么请把调用模块的函数放在显眼一点的地方,这样好在修改模块的时候修改对应的调用例如模块A,B,C有触发函数a,b,c,d那么新建一个空模块0与ABC并列,里面在同样位置放置函数a,b,c,d,但在里面调用ABC的a,b,c,d这是函数标签的替代,如果你是做前置的话当我没说4.计分板可以理解为数据类型,你可以设置int,bool,byte,tmp,float,result等计分板,而用假名区分它们放心大胆用不带命名空间的假名,只要不和自己冲突,写得舒服就行,硬要加命名空间可以加在计分项上面对于临时变量,建议采用不容易重复的函数路径名的一部分作为假名或路径,这样可以在降低记忆负担的同时减少bug但如果非常确信从创建到使用结束中间都没有其它函数插入的话,放心大胆地用类似# tmp,x tmp这种临时变量吧5.对于nbt路径,则可以用命名空间理解为数据类型,我经常采用temp辨别方式取决于它们的更新周期,temp是每tick随时有可能更新的东西,而init只在load时会出现变化,sys用来存储设置和状态一类的东西,也有可能随时变化6.状态这一概念是模块的属性,存在于模块的调用入口处,通过状态决定调用哪一个函数或者采用什么方案例如主函数可以有一个状态"stop",存在于主函数的tick函数,若为1则不调用后续的函数()可以采用计分板sys.stop state,也可以存在storage sys stop内使用这个东西可以把根据条件->调用不同函数变成根据条件->调整状态->调用同一个函数->根据状态调用不同函数这样,,有利有弊吧顺便玩家的潜行,疾跑,坐标,这一类也可以作为状态来理解可以存在玩家的计分板或者个人nbt空间里也可以存在player.xx state里,,毕竟是单tick内数据包才用得到的东西,在as@a的主函数里统一获取和使用就行了
#调试与控制 理想的情况应该是能随时暂停模块或数据包的运行而保持func的可调用所以用主函数的stop状态就行了只是进度要禁的话会麻烦一点点,但一般不禁也没关系吧,,
#命名与注释
旧贴 ##路径与<@s> 为了最大限度地避免重名,数据包使用的计分板和storage空间可以按照路径命名,以可以同时在文件夹,计分板以及storage内使用为标准例如s3_lib/functions/data/set_pointer.mcfunction的计分板名可以设置为s3_lib.data.set_pointer.success [计分板名,storage下的输出存储可以设置为storage data s3_lib.data.set_pointer{success:1b}路径的缩写规定为<@s>,例如上面的storage路径在注释里可以写成scb <@s>. successstorage data <@s>.success
##临时变量 data可以存在storage temp “<@s>”.变量名里,注意这里为了节省性能加上了引号以减少存储的级数,关于storage命名空间的使用见下(#data storage命名空间的使用)scb可以存在scb ##<@s>.变量名[类型]里,注意这里用了两个#,这设定作为临时变量的特有标志
##函数开头注释 函数的开头(系统函数除外)最好都标明输入、输出、运行环境以及函数的作用,没有可以留空可以在模块的__init内重新标明这个模块的路径为一个清爽点的样子(<@s> = xxx),不过注意重名 ( 由于写命名空间这样的东西很不爽所以在确定不会重名的情况下建议省略 )( 划掉 )
见 #最大化编辑维护体验
函数开头注释的话,第一行写这个函数干嘛的,第二行起写输入和输出用人能看得懂的语言写就行,注意输入包括执行位置和执行者,上一级不明的话可以写一下是哪个函数调用的它,以便查bug时方便些(前置函数就算了)主要的函数上写就行了
# data storage命名空间的使用规范建议
见 #最大化编辑维护体验:5. ##temp
#data和scb的数据储存和利用 首先比较一下两种方式 ##支持类型

以下是拿着不同的物品对应运行的函数,所有的存取量都是一样的(上图的21x100次)


我将从后面的格子滚动到前面的格子准备的工作为世界为虚空超平坦世界同时存在的实体数量为331,通过命令方块反复召唤药水云达到,这里不写了/summon minecraft:armor_stand ~~ ~{Tags:["test"]}/data modifyentity4c19e715-29b4-40f5-9cdf-37c6f7a0ba20 HandItems[0] set from entitysch233SelectedItem/setblock 0 3 0minecraft:jukebox/data modify block 0 3 0RecordItem setfrom entity sch233 SelectedItem/data modify storageminecraft:move1 moveset from entity sch233 {}load运行scoreboard players set #0 s3.Int0……………………………………………………scoreboard players set #19s3.Int 19data modify storage test 0 setvalue 0……………………………………………………data modify storage test 19 setvalue 19data modify storage testa.b.c.d.e.f.g.h.0set value 0……………………………………………………data modify storage testa.b.c.d.e.f.g.h.19set value 19data modify storagemove1move.Inventory[{Slot:0b}].tag.0 set value 0……………………………………………………data modify storagemove1move.Inventory[{Slot:0b}].tag.19 set value 19data modify block 0 3 0RecordItem.tag.0set from storage test 0……………………………………………………data modify block 0 3 0RecordItem.tag.19set from storage test 19execute as @e[type=armor_stand,tag=test]runfunction s3_math:main/func_tag/minecraft/load/_ss3_math:main/func_tag/minecraft/load/_s:data modify entity @sHandItems[0].tag.0set from storage test 0…data modify entity @sHandItems[0].tag.19set from storage test 19函数第一行分别以下图片,后续格式和上面的示例一样带@e的data存取

@s data存取

方块data存取

带索引的storage data存取

多级storage data存取

根目录storage data存取

计分板存取

###性能变化 前3个没有明显的区别0,1,2,3不运行,计分板运行,data根目录运行,data多级运行,多级运行的时候开始出现黄线了

3,4,5的区别data多级运行,data索引运行,方块data运行,索引运行的时候开始出现橙色的线,方块data运行的时候开始出现红线方块运行的消耗大概是多级运行的2倍

4,5,6,7的区别,可以看到非常的夸张啊data索引运行,方块data运行,实体@s运行,实体@e运行实体@s运行开始全是红线,是方块运行的两倍,@e运行直接超了一倍多的上限

由于前3个看不出性能,因此将存取量x10后再次测试不运行,计分板运行,data根目录运行,data多级运行,根目录运行消耗大概是scb的2倍,多级运行大概是根目录运行的2倍

把检索改为[0]后的测试(10倍强度),反而比多级测试占用还少,毕竟只有5级(其中一级是[0]),而多级有9级注意这个时候比根目录消耗大不了多少,看起来[0]和普通索引差不多的样子
我们把[0]改为move.Inventory2[0][0][0][0][0][0][0]试试

[0]的引用和直接的引用消耗是一样的好家伙,消耗表出来了(20tps=40消耗,拿尺子量的,图之间的比例差的有点大,取了近似,仅供参考)scb:1.1data{1级}:3.6data{5级}:5data{9级}:8.4data{5级其中一级索引}:10block:17.4@s数据存取:40
@e数据存取:113
@e在不进行对实体的数据存储且全世界实体数量不多的时候性能消耗十分低
data的存储能力很强(支持各种类型),有清晰的存储结构,找东西很方便,能进行较为方便的读取和编辑操作但是卡,即使是根目录的data读取,消耗的时间也是scb的两倍以上,不建议在tick中常调用data的数据(比data更卡的是实体,卡顿随着数量增长而且固定有一定的层级)scb性能很好,目测性能不受名字长度影响,而且可以进行各种数字计算(data不行),结构简单而且有长度限制,假名设定后很难找到,仅支持整数存储建议直接把data当成硬盘操作,scb当成内存操作,每次load都把data转化为计分板(划掉)建议直接把data当成堆操作,scb当成栈操作,除了引用很麻烦之外一切都好(划掉)
#nbt与predicate的性能区别 做这个完全是出于@Jokey_钥匙 的请求的,这里可以看见predicate比nbt到底快了多少倍,,为了比较的公平性,我们所有的predicate判断都采用泥土采用的循环次数和上一节一样,并且统一采用@s
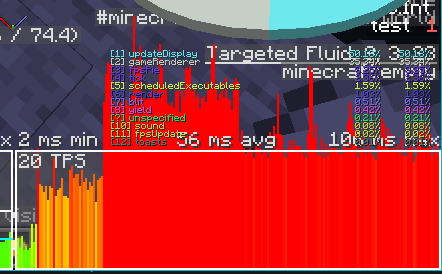
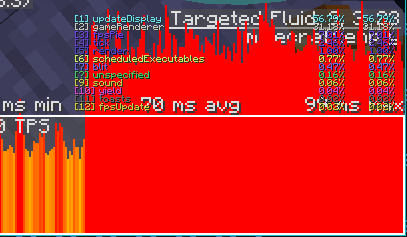
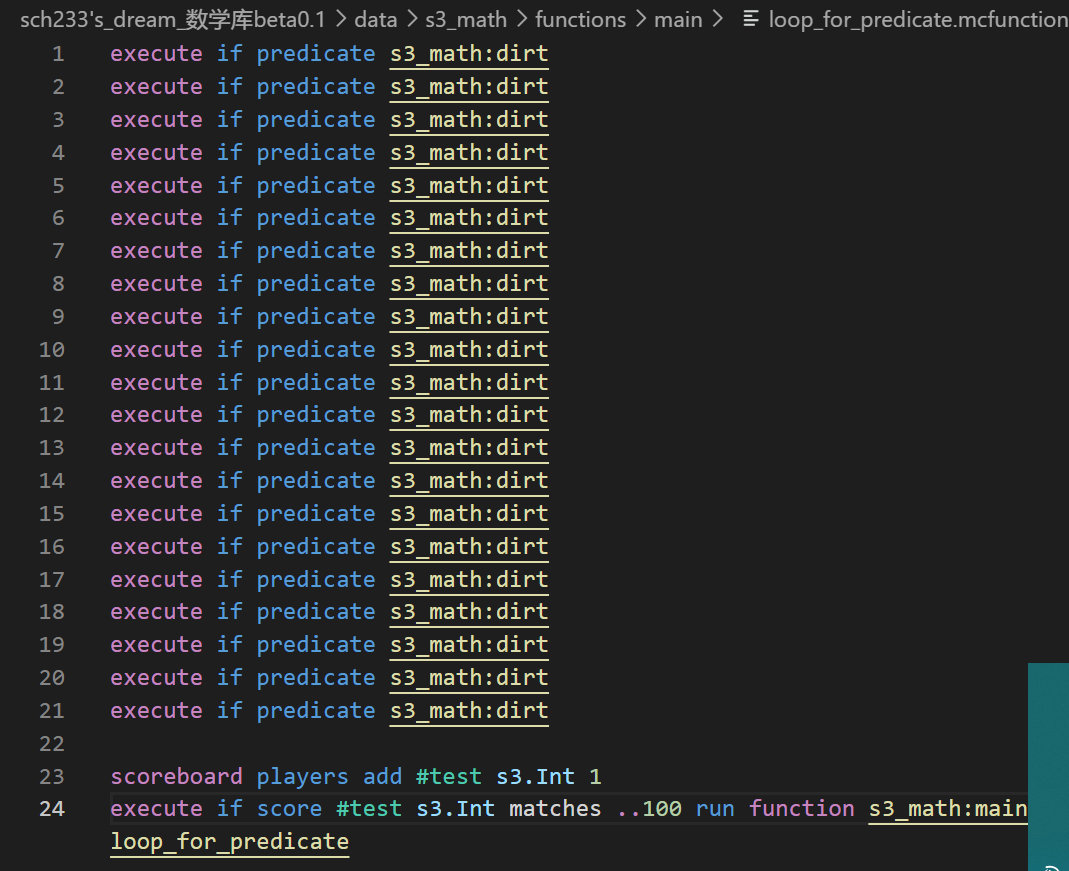
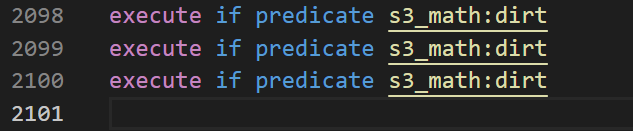
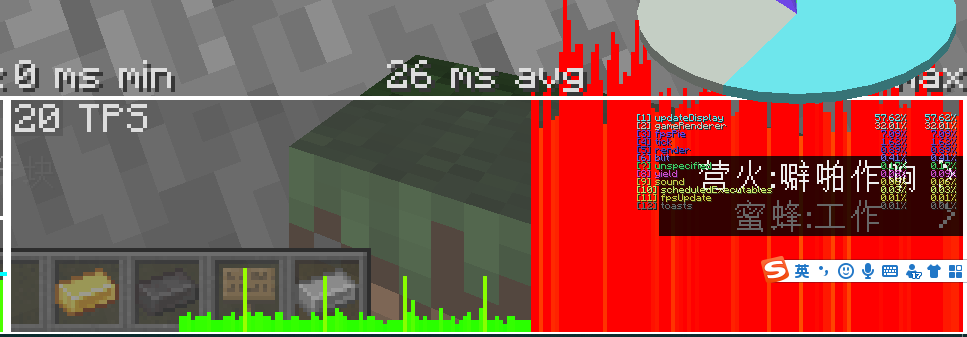
这里把两种nbt判断都用上了并且为了得到更纯粹的性能比较,直接复制粘贴了2100个第一张图是按照与上面一样的方式测试的



右边就和上一节的@s的结果差不多,而用predicate简直和data storage没几级一样(还是比计分板慢的)
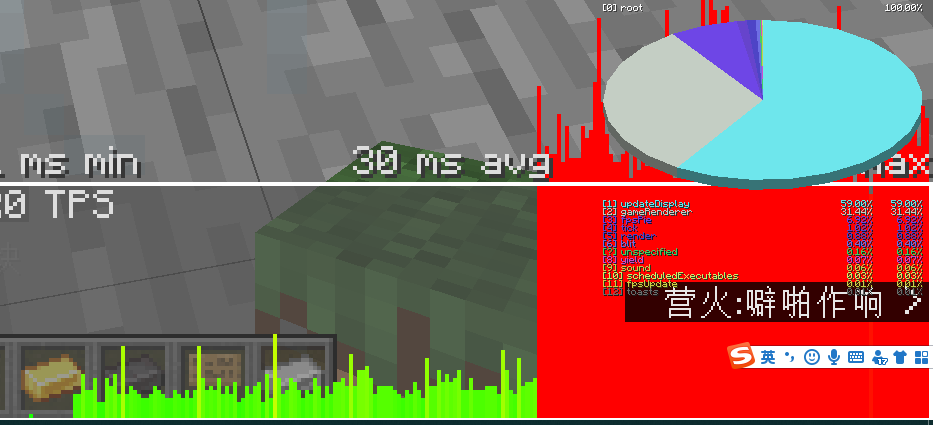 更为纯粹的性能比较
更为纯粹的性能比较
 #计分板极限
众所周知计分板的极限是2147483647也就是int的上限,但在这个极限附近进行运算会怎么样呢经过测试,运算结果如下2147483647 += 1 结果-2147483648-2147483648 -= 1 结果21474836472147483647 *= 2 结果 -2-2147483648 *= 2 结果0-2147483648 += -2147483647 结果1-2147483647 *= 2 结果2-2147483648 *= -1 结果-2147483648很显然计分板的运算是按照
补码
(
百度百科
)进行的,运算方法不知道的可以自己去看
#计分板极限
众所周知计分板的极限是2147483647也就是int的上限,但在这个极限附近进行运算会怎么样呢经过测试,运算结果如下2147483647 += 1 结果-2147483648-2147483648 -= 1 结果21474836472147483647 *= 2 结果 -2-2147483648 *= 2 结果0-2147483648 += -2147483647 结果1-2147483647 *= 2 结果2-2147483648 *= -1 结果-2147483648很显然计分板的运算是按照
补码
(
百度百科
)进行的,运算方法不知道的可以自己去看
## 这里谈一谈我的理解 ( 警告:以下的图和补码的实际运算方式没有任何关系,仅为我个人理解! )

采用补码的优势是所有的减法都可以转化成加法在结果不溢出-2147483648~2147483647的情况下在0~2147483647内,加法可以看作是两个补码直接相加在-2147483648~-1内,加法也可以看作两个补码直接相加两个数分别在两边时,加法还是可以看作是两个补码直接相加多余的1会溢出一位而舍掉,得到的结果是正确的
##int当成unsignedint 可以看到补码从-2147483648~-1,去掉符号位与0~2147483647是一样的事实上绕一圈回来和unsigned int的存储是一致的这意味着,int完全可以当成unsignedint来使用,加法方面不成问题
##改变符号位 如果把任意scb加上-2147483648(也就是仅改变符号位) ,0和±2147483648的意义会对调,负数对调后的值就是负数-(-2147483648)的值,正数对调后的值就是正数-(2147483648)的值-2147483648---------负数---------0----------正数--------------2147483648通过这种办法可以得到到底溢出了2147483647或者-2147483648多少值
#数据类型判断与筛选
##废话 我在第五版数据包设计的可以让玩家用一条命令输入多个函数参数并运行的东东,可以确定的有as,at,positioned,rotated,return(tellraw返回值)的对象以及任意数量的参数,甚至能一条命令运行多个函数,只要你聊天栏装得下但是做这个的过程中遇到了问题:怎么判断玩家输入参数是不是符合函数运行需求的呢?要知道玩家的输入是最无法预料的,而且你也不会知道自己的函数在各种乱七八糟的输入下会有什么反应,因此判断并筛选数据类型势在必行我经过反复尝试和各种灵光一闪,最终找到了以下的判断和筛选方法
##data允许的所有类型 参考 这里
##{}和[]类的类型 使用
##所有数字和字符串
可以利用数组下所有元素必须类型一致的特性
先给每种元素创立一个数组
data merge storage type set value{byte:[1b],int:[1],short:[1s],long:[1L],float:[1.0f],double:[1.0d],str:["1"]}
然后要判断的时候复制对应的类型的数组到storagetemp,
再store successxx run data modify xx.<type> append from 你要判断的值
就行了
##两种字符串的判别 指""型和'{"text":""}'型的字符串的判别,我在这里简称为str和str+它们同时存在于一个数组中是不会报错的 那我们就只能通过方块或实体来判定了 更改告示牌的内容为storage内容的显示 不加上 interpret,str会正确显示而str+不会,
它们在告示牌上存储的内容都改变了,
str的形式会转变为str+的形式,
str+则会在里面加一堆反斜杠,
用data复制回去都会返回成功所以不能用于辨别
更改告示牌的内容为storage内容的显示 加上 interpret,str+会正确显示而str不会,str的的在告示牌上的存储为空,用data复制回去会返回成功,str+在告示牌上的存储不变,用data复制回去会返回错误所以可以采用第二种方法来进行判别,届时比对是否发生了改变即可 以上方法在以str+作为存储方式的实体和方块上应该都有效
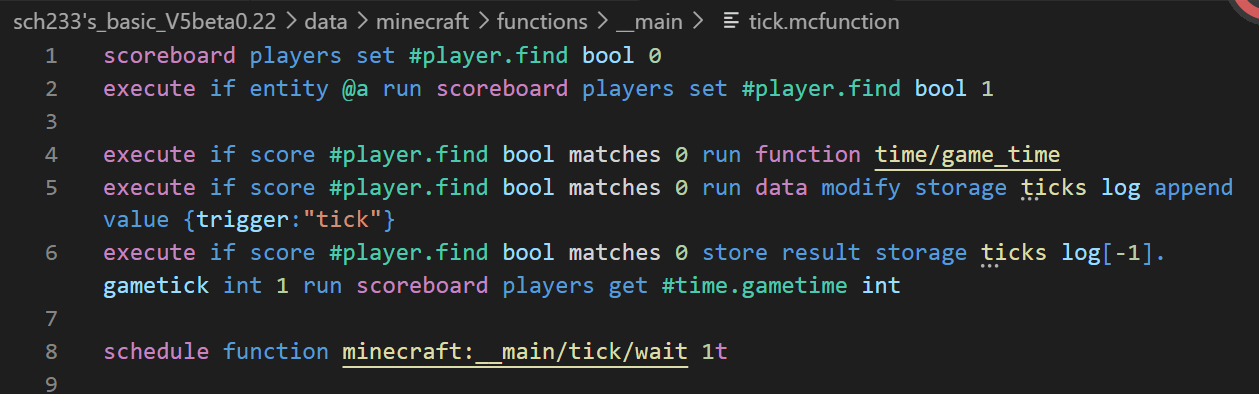
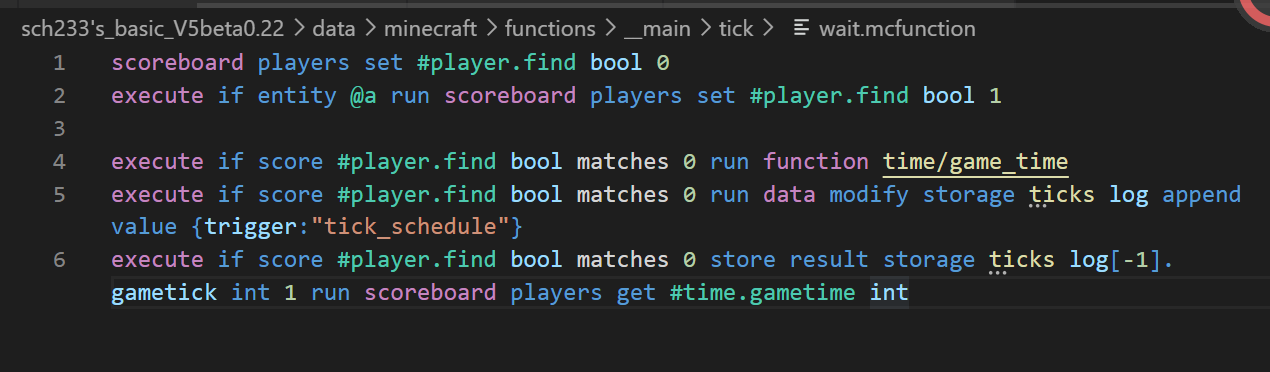
#游戏更新顺序
##load 众所周知在load的时候是检测不到玩家的,那么在世界开始加载到玩家进入这段时间到底运行了几次tick或schedule呢
采用添加数据进data的方式,我们可以看看加载顺序是什么样子的
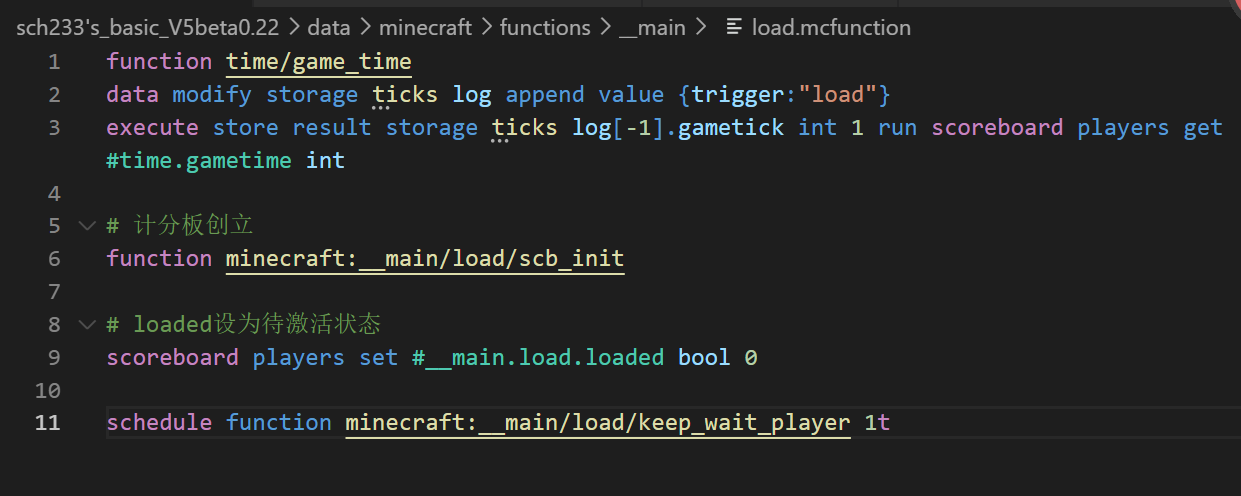
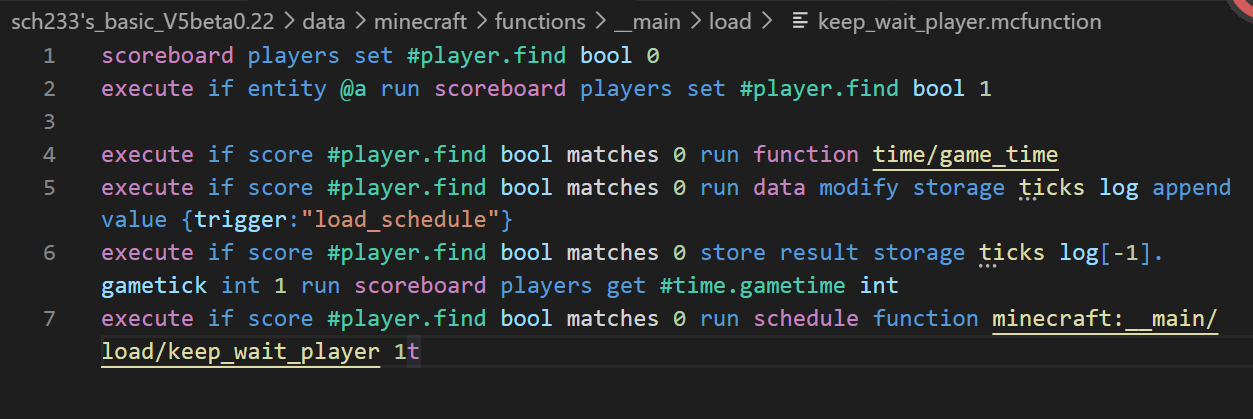
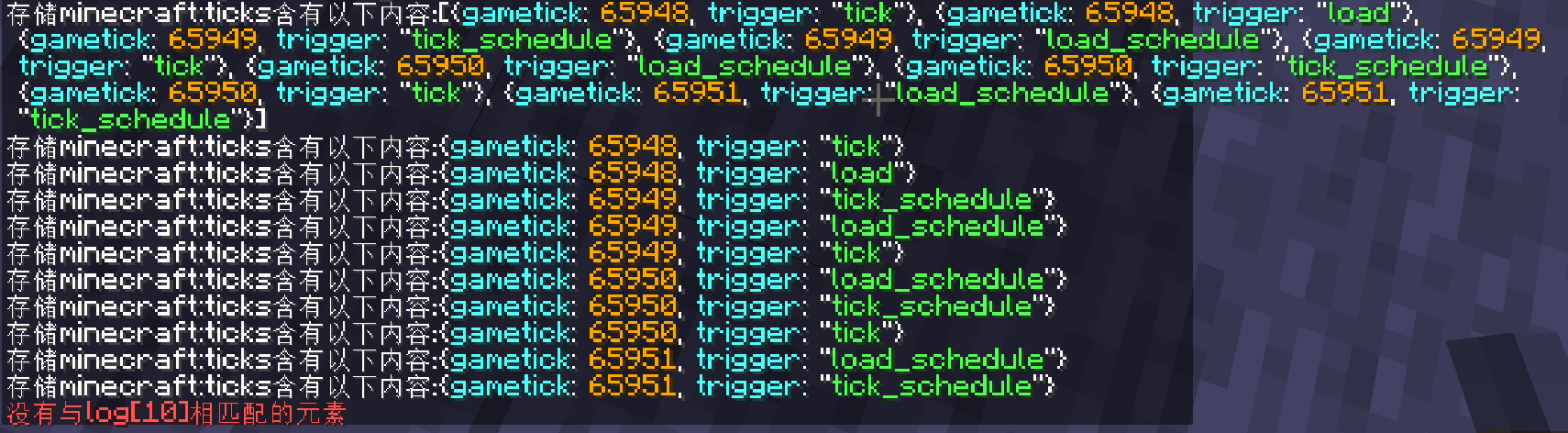
tick,load
tick_schedule,load_schedule,tick
load_schedule,tick_schedule,tick
load_schedule,tick_schedule,玩家进入(,tick...)
看起来gametick是在tick后schedule前刷新的,, ##tick ##直接上图 打算测试的触发方式有tick,advancements,循环型命令方块(RCB),schedule,以及玩家触发的指令所有的指令都是以玩家的计分板不是233为前提条件运行的直接运行,能够得到大概的运行顺序
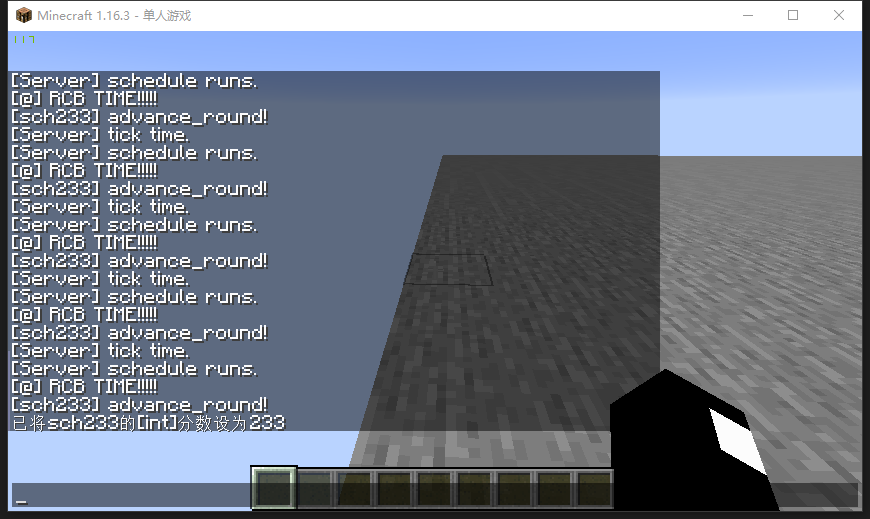
改一改输出,让它们能输出玩家的坐标

然后飞到万米高空掉下
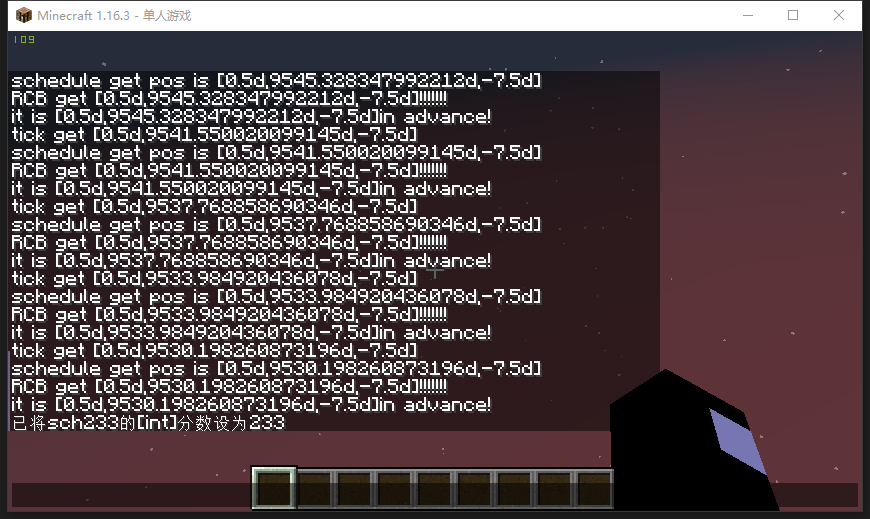
tick得到y=9530.198schedule得到y=9530.198RCB得到y=9530.198advance 得到y=9530.198玩家执行命令现在我们基本上可以确定顺序了,玩家执行命令和游戏更新的顺序不清楚似乎并没有啥影响 ? 我觉得可以测出来再改进一下

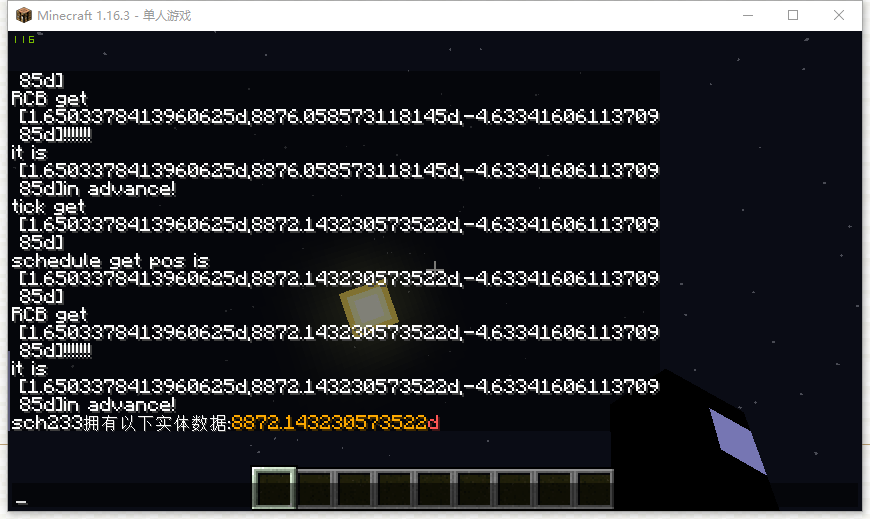 然后我测试了一下丢物品
然后我测试了一下丢物品
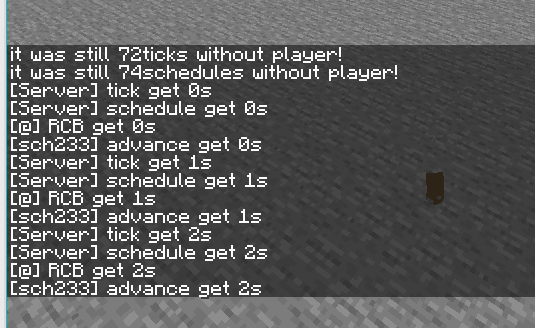
发射器丢物品
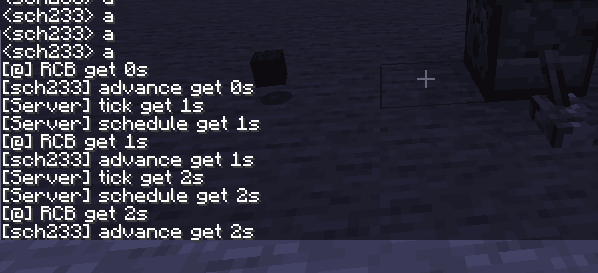
结果: tick->schedule->发射器 丢东西出现Age ->RCB->advancement-> (玩家命令->玩家坐标更新)(实体Age更新->玩家丢出的物品出现Age) 然后又测了一个,测试的方式是按钮加中继器配合两个命令方块改计分板控制开启检测并输出到data,懒得截图了,把结果放出来吧
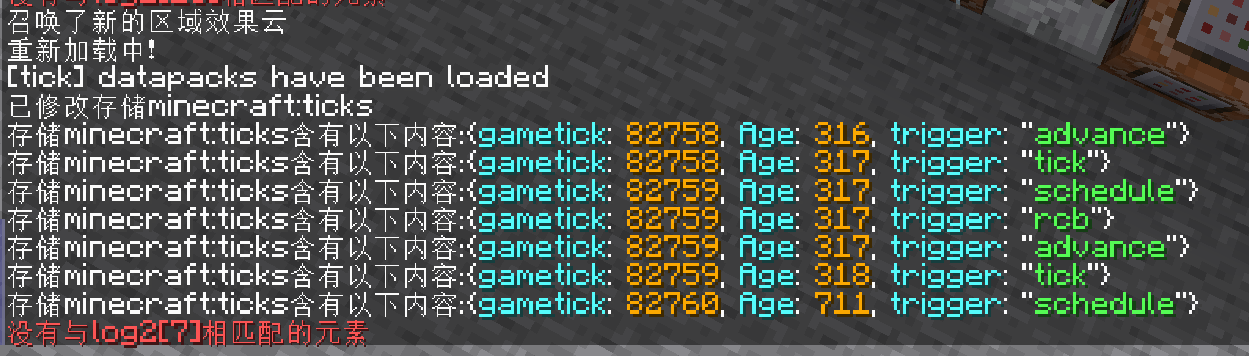
【gametick更新】schedule更新【发射器更新,红石中继器导致的命令方块更新】rcb更新【玩家按按钮导致的命令方块更新】advance更新玩家命令执行【药水云Age更新,玩家坐标更新,玩家丢物品更新】tick更新【下一个gametick更新...】
#杂项
##性能与体验 所有tick触发的函数的运行以性能为优先,尽可能使用计分板传参(见下的#data和scb的数据储存和利用);玩家主动触发的函数一切以使用体验为优先,如果data方便就data来(因为玩家主动触发的通常不会太影响性能),给玩家调整参数和值的东西以data为优先(因为方便找和查看),必要的话可以搞专门的函数来显示和操作
##marker设置 所有类型的marker,不管是药水云盔甲架物品展示框还是为了处理数据包放置的其它什么实体都好,统一加上Marker的tag以防止在kill的时候误杀
# 各种存储或判断方式的性能测试
数据包结构 、 各种存储或判断方式的性能测试、以及游戏更新顺序的测试
本帖还有很多不完善的地方
欢迎提供移除、修改和补充的意见
本帖有许多零碎的东西,持续不定期更新
“
写写分别的特性和性能比较
并写写在计算中的利用方式和一些技巧
最重要的是给出你的
data
规范
”
——Xiao2
#
写帖起因
我之前的数据包用
data
用得挺少,函数之间传参也挺少的
在搞第五版数据包的时候,打算模仿类的样子来写,然后第四版的
basic
分成了底层和基本库两个数据包,底层用来处理各种不那么优雅的东西,然后基本库就可以写得更优雅一点了
即使我在开始编写的时候心中有了大致的规范,但实际编写的过程中,随着函数的增多,数据包越来越乱,越来越不优雅,我意识到我可能需要把这些规范更加清楚地整理一下
而且在写各种函数的时候由于函数允许的输入输出变多了很多,想兼顾效率和使用体验以及编辑体验以及可拓展性,,,,计分板和
data(storage,entity,block)
的存储和使用各有优劣,搞的我头都大了,加上
@Xiao2
的建议,就写了这个帖子(并进行了一些测试)
然后测试越来越多。。。。
#
点击目录翻页
!!
2021.12 数据,可能有更多内容
数据包结构 、 各种存储或判断方式的性能测试、以及游戏更新顺序的测试
本帖还有很多不完善的地方 欢迎提供移除、修改和补充的意见 本帖有许多零碎的东西,持续不定期更新 “写写分别的特性和性能比较并写写在计算中的利用方式和一些技巧最重要的是给出你的data规范”——Xiao2 #写帖起因 我之前的数据包用data用得挺少,函数之间传参也挺少的在搞第五版数据包的时候,打算模仿类的样子来写,然后第四版的basic分成了底层和基本库两个数据包,底层用来处理各种不那么优雅的东西,然后基本库就可以写得更优雅一点了即使我在开始编写的时候心中有了大致的规范,但实际编写的过程中,随着函数的增多,数据包越来越乱,越来越不优雅,我意识到我可能需要把这些规范更加清楚地整理一下而且在写各种函数的时候由于函数允许的输入输出变多了很多,想兼顾效率和使用体验以及编辑体验以及可拓展性,,,,计分板和data(storage,entity,block)的存储和使用各有优劣,搞的我头都大了,加上@Xiao2的建议,就写了这个帖子(并进行了一些测试)然后测试越来越多。。。。
#点击目录翻页!!
#函数结构 可以去这里看一下( 函数命令系统 )
##mcf调用-if结构 MC中的if结构只能通过调用mcf来减少重复判断可以采用execute if xx 结构来进行判断可以先采用execute store 存储特定命令的返回值后再进行判断来达到更广的判别范围建议用计分板作为if控制的条件
###且(&&)与或(||) execute 命令自带且的逻辑,只需要叠加上去就行想要实现或的逻辑的话,需要放多个并排的execute if,并且保证两个条件没有交集以防被执行两次,或者用!((!a)&&(!b))也行用后者大概是这样not_found=0exe unless scb==a unless scb==brun not_found=1exe if not_found==0 run func…
###并排使用executeif 注意并排使用if的时候,if的条件在执行的函数内不应该被改变,否则可能会出现意料之外的效果建议并排使用if的时候新建一个关于if的临时计分板作为控制,而不是直接使用条件并排实现或大概是这样scb_ = scbexe if scb_== a run func..exe unless scb_ == a if scb_ ==b run func
###if else结构 If else的执行原则就是从第一个条件判断开始,一路往下进行判断,遇到符合的条件就执行并且不再判断后面的代码块,如果没有符合的条件,则执行else下的代码块为了达到效果需要创立另一个计分板用mcf写大概是这样temp = conditionfind = 0not_de =0#一般条件exe if find ==0 if temp == a runfunc Aexe if find ==0 if temp == a runfind =1#且exe if find ==0 if temp == b iftemp == c run func Bexe if find ==0 if temp == b if temp== c run find =1#或exe if find ==0 unless temp == dunless temp ==e run not_de =1exe if find ==0 if not_de ==0run func Cexe if find ==0 if not_de ==0run find =1exe if find ==0 run func ELSE
###断言方式的利用形式
参见
断言提供丰富的逻辑结构,包括
- “或”minecraft:alternative
- “且【非(非A或非B)=A且B】”
-
“非”minecraft:inverted
##mcf调用-循环结构 MC的所有循环结构只能通过在mcf末尾 有条件 地调用自己来达到,这是一种递归(自己调用自己) 建议所有这样的函数都在前面加上loop以方便识别比如这是一个死循环,不管以什么方式触发,一旦运行就无限递归然后循环到每tick命令上限
loop_a.mcf a += 1func a
这是一个正常点的循环,运行loop_a,b会运行100次然后结束,并输出100,所有运算都是1tick内完成的,并且中途不会运行其它任何其它mcf或进行任何其它计算(废话)
loop_a.mcf scb=0max=100func bsay scb
b.mcf scb += 1if scb <max run func b
改一下就变成了有点用处的函数,运行loop_a就能计算1加到100的值,并输出5050
loop_a.mcf scb=0max=100value=0func bsay value
b.mcf scb += 1value += scbif scb <max run func b
###列表递归 MC允许通过<路径>[num]来读取列表内的元素,但num却不能接受来自计分板或data的参数,因此在数据包中通常选择第0位读取,加上递归的方式来遍历列表
#检测列表list中uid为<scb>的项,并输出对应的name a.mcf check = <scb>data temp_list =data listexe if data temp_list[0] runfunc loop_say_name
loop_say_name.mcf uid = data temp_list[0].uidexe if uid == check run say datatemp_list[0].namedata remove temp_list[0]exe if data temp_list[0] runfunc loop_say_name
列表的方法也能用在数组上,两者在使用的时候差不多
##循环体 这是@Xiao2提出的一个概念,基本逻辑是把单tick内的循环拆分到多tick内分步执行,通常附带一个参数作为循环上限,也可以不附带参数,这样需要被调用函数主动结束循环像一个临时触发,持续一段时间的tick启动计分板key可以在任意函数的任意地方开启和关闭,甚至可以暂停一段时间然后继续运行循环体的一个重要特性是没有用到任何的递归,无循环上限的循环体和无条件的schedule循环差不多例子#当运行a的时候让玩家向前冲刺一段距离(无视方块)
代码:
-
=【a.mcf(手动触发)】:
-
#开启循环体
- key=1
代码:
-
=【b.mcf(tick run)】:
-
#循环体
-
if key ==1 run time += 1
-
if key ==1 run func dash
-
if time == 20 run key =0
- if time == 20 run time =0
代码:
-
=【dash.mcf】:
-
#实际运行函数
- tp @s ^ ^ ^1
#复杂一点的冲刺(输入时间速度,简单区分方块,用到了递归)
代码:
-
=【a.mcf(手动触发)】:
-
time=<设定时间>,单位t(0.05s)
-
speed=<设定速度>,单位m/s
-
#开启循环体
- key=1
代码:
-
=【b.mcf(tick run)】:
-
#循环体变式,时间不定
-
if key ==1 run time -= 1
-
if key ==1 run func b_cyc
- if time == 0 run key =0
代码:
-
=【b_cyc.mcf】:
-
#实际运行函数
-
dash_temp = speed
- if dash_temp >0 at @s positioned ^ ^ ^0.05 run func dash
代码:
-
=【dash.mcf】
-
if block ~ ~ ~ #solid run func stop_dash
-
dash_temp -= 1
-
if dash_temp ==0 run tp @s ~ ~ ~
- if dash_temp >0 positioned ^ ^ ^0.05 run func dash
代码:
-
=【stop_dash.mcf】
-
dash_temp =0
- key=0
代码:
-
=【a.mcf(手动触发)】:
-
int1=x
-
int2=y
-
value = 0
-
#开启循环体
- key=1
代码:
-
=【b.mcf(tick run)】:
-
#循环体变式,无法自动结束
- if key ==1 run func b_cyc
代码:
-
=【b_cyc.mcf】:
-
value +=int1
-
int1 += 1
-
if int1 > int2 run key=0
- if int1 > int2 run say value
代码:
-
=【tick.mcf(tick run)】:
-
#limit=<设定的上限>
- if @e[tag=cut_start,tag=cut] run key=1
代码:
-
=【b.mcf(tick run)】:
-
#if key==1 run limit -= 1
-
if key==1 run func b_cyc
- #if limit ==0 run key=0
代码:
-
=【b_cyc.mcf】:
-
at @e[tag=cut] run setblock ~ ~ ~ air destory
-
at @e[tag=cut] run func new_cut
- unless @e[tag=cut] run key=0
代码:
-
=【new_cut.mcf】:
-
if block ~ ~1 ~ log positioned ~ ~1 ~ run func set_cut
-
if block ~ ~1 ~1 log positioned ~ ~1 ~1 run func set_cut
- ....
代码:
-
=【set_cut.mcf】:
- summon AEC ~ ~ ~ {Tags:["cut"],Duration:2}
##schedule循环 这大概是广为人知的一个循环方式(大概),函数通过schedule调用自己可以产生tick循环的效果,并且可以根据需要随时开启和终结,或者设置条件让其自己终结,产生类似循环体的效果无条件的schedule循环可以代替tick,只要从load开始就行,唯一的不同是schedule是在所有tick执行后再执行的建议无条件循环的schedule循环的mcf前面加上keep
#这是一个普通的schedule循环,作用是一直say hi
代码:
-
=【keep_say_hi.mcf】
-
say hi
- schedule func keep_say_hi
如果我要开始say hi,那么运行func keep_say_hi就能一直say hi了如果我要结束say hi,那么运行schedule clear keep_say_hi就能结束say hi了 #玩家向前冲刺一段距离(无视方块)
代码:
-
=【dash.mcf】
-
exe at @s run tp @s ^ ^ ^1
-
time +=1
-
exe if time == 20 run time =0
- exe unless time == 0 runschedule func dash
#砍树连锁(有很多省略)
代码:
-
=【tick.mcf(tick run)】:
-
limit=<设定的上限>
- if @e[tag=cut_start,tag=cut] run func cut
代码:
-
=【cut.mcf】:
-
at @e[tag=cut] run setblock ~ ~ ~ air destory
-
limit -= 1
-
exe if limit > 0 at @e[tag=cut] run func new_cut
- exe if limit > 0 if @e[tag=cut] run schedule func cut
代码:
-
=【new_cut.mcf】:
-
if block ~ ~1 ~ log positioned ~ ~1 ~ run func set_cut
-
if block ~ ~1 ~1 log positioned ~ ~1 ~1 run func set_cut
- ....
代码:
-
=【set_cut.mcf】:
- summon AEC ~ ~ ~ {Tags:["cut"],Duration:2}
这个比上面的循环体更为简洁
##函数:向下套娃以及_def0 在简写里面已经说过了函数的定义,函数能创建同名的文件夹与自己并列,然后这个文件夹就也是自己的一部分这里可以进行套娃,来进行大量函数的有效整理,比如可以创建一个_def0函数来定义所有需要的触发器建议调用自己同名文件夹下一级所有mcf的函数前方加上一个下划线(_),并且在后方加上分别层级的数字例如
代码:
-
=【__main/func_tag/Minecraft/tick.mcf】
- exe as @a run func player/tick
代码:
-
=【player/_def0.mcf】
代码:
-
=【player/_def0/sneak.mcf】
-
sneak = 0
- exe if @s[predicate=s3_lib:sneaking]run sneak = 1
代码:
-
=【player/_def0/r_click.mcf】
-
r_click = @s carrot_on_a_stick
- @s carrot_on_a_stick = 0
代码:
-
=【player/_def0/trigger1.mcf】
-
trigger1 = @s trigger1
-
@s trigger1 = 0
- enable @s trigger1
代码:
-
=【player/_def0/_def1.mcf】
- func player/_def0/_def1/super_shot
代码:
-
=【player/_def0/_def1/super_shot.mcf】
-
super_shot == 0
- exe if sneak ==1 if r_click == 1run super_shot = 1
代码:
-
=【player/tick.mcf】
-
func player/_def0
-
exe if super_shot ==1 run func <super_shot>
- exe if trigger1 ==1 run func <trigger1>
## 函数:向上套娃以及继承 复制粘贴可以在最广泛的方面达到继承的效果,但是会增大数据包以及维护的量 如果结构允许的话 先写好一个模板然后通过直接调用函数来继承是最好的(可以参考我的棋盘数据包,,) 关于函数标签,如果你没打算做前置,就不需要使用,所以这方面我的棋盘数据包滥用了函数标签呜呜呜。。。
旧贴(别看,别看,我说了别看)
###指导总纲: 面向对象思想(参考链接: 百度百科 知乎 简书 ) 本文主要提供数据包的结构以及规范的建议这些东西和本文没什么关系,但是讲得的真的不错(除了百度百科)
###类与对象 这里的模块对应的就是类,函数对应的就是类的方法 子模块放在父模块的文件夹下, MC的数据包并不完全支持继承(你要完全不考虑效率当我没说),这里对继承进行了一点点尝试 以下结构可以进行一定意义的继承,但并不完全适用于 MC ,请斟酌使用
### __import函数 模块下可以有一个__import函数,用来进行模块的继承,以及模块内函数的调用 如何理解见上面的指导总纲,每一个模块的__import函数都被所有子模块的__import函数调用,同时调用父模块的__import(如果有父模块),并且根据func_uid调用本模块的所有函数
###多重继承 __import的结构允许多重继承 仅继承一个模块的模块放进父模块的文件夹下与父模块的其它函数并列 继承多个模块的模块作为根模块放到functions下第一级 同时__init由load调用而不是父模块的__init 多重继承的func_uid通常会有冲突,需要在__import内自行决定是都调用,还是按情况进行选择 使用的临时变量可以命名为scb ##<@s>.__import func_uid或者storage temp{“<@s>.__import”:”func_name”}
###func_uid与函数 __import判断调用哪一个函数的计分板规定为scb ##import func_uid,每次使用的时候都要重新设定 func_uid对应哪一个函数名可以有以下3种方法,第一种和第二种不冲突 #函数名 将函数命名为<func_uid>_<func_name>
- 优点: 编辑时可以直观方便地看出函数对应哪一个func_uid,玩家运行/function时也能迅速分辨可执行的函数
-
缺点: 难看,而且会让人犹豫要不要把路径替换为和函数名一致的难看,函数名和func_uid要做到严格对应得自己去再建一个函数表
- 好处: 可以严格对应
-
缺点: 编辑的时候不能直观地找到函数对应的func_uid,而且改对应关系的时候问题更大
- 优点: 没有上面的所有缺点
-
缺点: 找函数的效率会变成原来的一半左右,对小的函数影响尤为明显
###多态 重写可以在__import内上一级__import的调用之前检测对应的函数号,并在之后清除计分板的值 重载同理,不过在新的函数内要if调用旧的函数,达到添加新的输入参数类型的目的 如果要筛选一般的参数的话,可以见下#数据类型判断与筛选,但碰上更复杂的就不行了,建议附带一个额外的参数来选择函数模式,启用或禁用一 部分的代码块 因此__import内[重写或重载函数的调用必须在[父函数的__import的调用之前
#数据包结构 前置教程(不是)
#观看前可以参考
- 了解数据包的结构, 这里是wiki
- execute的全部基础使用方法,可以跳转 这里
- data的全部基础使用方法,可跳转 这里
- scb的全部基础使用方法,嗯,,我估计你们应该都会 这里有一份古老的详细教程
- 去 入门教程 入门一下(这个入门教程一点也不入门,更适合当字典来翻)
- 一些 数据模块
-
总结的
命令变动
#这里是简写
- mcf = mcfunction
- scb = scoreboard
- AEC = area effect cloud
- 模块 – 指同一级文件夹内没有同名mcf的文件夹,同时人为规定不允许mcf出现在functions下第1级,也就是functions下所有文件夹都是模块,规定functions下的模块也叫做根模块
- 函数 – 所有可以独立完成特定任务的mcf统称函数,函数可以创建同级同名文件夹作为自己的一部分,其中只能放置所有的仅被自己直接或间接调用的mcf
- 运行环境 – 包括execute as,at(positioned, rotated, facing...), in等;
- 函数参数 – 指函数的输入参数,这里指来自于计分板和data的参数
- __xx – 前面加两个下划线表示这是系统调用相关的东西
-
触发器 – 当满足一定条件时运行mcf的结构,主体必须存在于(某种意义上)无条件tick运行的mcf中
废话一堆
#必要性以及原因
- 嗯,,,,
- 一个数据包之中,真正起作用的只有一部分函数,
- 而相当的内容则用于控制这些函数什么时候,在哪里,以什么形式什么顺序触发(如何将函数从tick\load\advancement调用到目标函数)
- 这些触发器编写起来往往占据了很多时间,而不能让数据包作者把自己的精力单纯地放在功能的设计与实现,
-
而是放在功能怎么触发,文件放哪里,变量名怎么取这种问题上(变量名冲突以及难记以及有长度限制的问题,建议MoJang出一个function内临时变量)
- 加上MC长长的不易读取的命令更是加剧了难度
- 文件夹一乱,维护更是成为了相当令人头疼的事情(所以文件夹结构也是个重点)
- 各个数据包的触发器不一,会导致很多东西比如视线检测和各种判据重复运行,(触发器统一)
- 容易占据很多不必要的性能,或者干脆导致这些触发器成为了尽量避免的东西
- 这些显然是我们不愿意看到的
-
如果这些东西能够标准化,那么能解决以上几乎所有问题
- 在一切开始之前,我们需要一个放置mcf文件的地方
-
所有的一切从文件夹结构开始
#文件夹结构的矛盾
- 文件夹结构的分类大致可以有两种方法,以执行顺序为基准和以执行主体为基准[spoiler]
- 以执行顺序为基准大概是直接把tick.mcf和load.mcf放在最下面,然后上方放一个tick文件夹,一个load文件夹就可以完工了,再简单点甚至不需要tick和load文件夹
- 所有其它的东西都按照顺序触发,甚至可以编个号
-
以执行主体为基准大概是根目录下一堆文件夹而见不到mcf,每个文件夹内是差不多的结构,tick.mcf和load.mcf平均分布在每个文件夹内,而每个文件夹之间调用甚少
- 前者更适合集中处理,而后者更适合模块化处理(当然不意味着就这两种方法,这只是两种完全不同的思路)
- 对于触发器而言,毫无疑问需要集中式处理才能提高效率
-
而当组件数量增多的时候,只有模块化处理才能使数据包变得可维护和易于拓展
- 单纯做小数据包的话前者就够用了,甚至是最好的方案,
- 但数据包大起来的时候就不得不采取混合甚至完全后者的方式来布置文件夹结构
- 这样要么会让数据包变得结构混乱反而难以维护,要么会产生大量毫无意义的消耗,两者都是难以接受的
-
这是我做数据包的时候相当矛盾的地方
(2021/7/25)
- 直接采用后者啊,为啥以执行主体为基准里面就必须得是一样的了
- 顺序为基准也是一种主体来着,
- 命其高频部分为主函数部分
- 触发器是触发器部分,包括初始化
- 待玩家调用的部分
- 前置部分(
- 功能部分
-
剩下的都是其它函数部分
#解决方案 旧贴
-
毫无疑问,我们需要一个基础模块,而且这个基础模块应当是对修改封闭,对拓展开放的(面向对象警告)
(发帖的时候)
-
基础模块另开一个数据包的想法已经有了,但我这时候还是有想要在模块化的数据包内控制运行顺序的心思,所以整了一个系统模块
(指发帖后过了好多天的,对于今天而言的,前几天)
- 这个东东是不是每个数据包内都开一个一模一样的命名空间,然后选择性地删去不需要的mcf比较好,而不是作为独立的数据包而存在?
- 由于MC的数据包合并功能这些功能并不会重复触发,json也能合并
-
这样就能够提供触发器的同时不破坏模块化的整体结构,而且还能控制不同功能的开启来减少功能的浪费,我就能往基础模块里塞爆了()
(今天2020/12/20)
- 这样就塞了一段时间,但后来又想啊,删mcf来控制开启还是太不人性化欸,加计分板来控制维护太麻烦,storage控制又挺浪费性能,
- 既然函数标签能导出,那么也用函数标签来导入,用其控制模块功能的开启好了,只要都统一塞#tick或者#load下就不会有重复触发
- 这样基础模块就经历了 模块化的性能浪费->集中化的编辑麻烦->再度模块化 的这样一个过程,现在正在写数据包的结构大概是近似前几天那一种的结构,但估计又得重构
-
由于已经不想要在不同模块间控制执行顺序(在基础模块里上就行了),所以我认为系统模块也没有必要了,tick和load,或者其它触发器留在每个需要的模块内
(2021/7/25)
- 能有人用数据包就不错了,考虑个屁的通用性
- 所以一切以优化数据包编写体验为优先才对,这样才能促进作品的产出
-
小豆的数据包震撼我妈
#最大化效率 旧贴
理想的情况应该是数据包作者根据自己的数据包需要的功能选择需要启用的触发器,
数据包制作者可以根据需求定义和组合触发器然后所有的触发器经过加载后转变为计分板的被检测形式通过检测计分板来触发函数
就算同时安装了这个前置的其它数据包,基本模块定义的触发器的检测不会执行第二遍
如果命名够规范的话也能做到一部分的自定义触发器检测不会执行第二遍
若想尽可能缩减消耗的话,尽可能少用选择器才是对的而主函数部分是选择器泛滥的区域,,显然大家不可能都用同一个主函数模块但可以在自己的数据包内采用主函数模块例如有了一个as @a run xx ,其他的as @a 就不用写了,全部都放进这个函数吧(能用function就不要大规模穷举,除非看着更舒服能用计分板就尽可能使用计分板用nbt时尽可能减少路径层数,尤其是大规模穷举或递归时,可以直接加双引号把路径括起来变成一层路径(划掉),但只要不是这种情况,还是以方便理解为优先
#最大化编辑维护体验 旧贴
理想的情况应该是数据包制作者能比较方便地创建和管理自定义的触发器并且所有的函数都由定义的触发器直接或间接地触发所有文件模块化,并能迅速明白这是干什么用,怎么用的把tick/refresh这样的,load这样的,平等地看成触发器模块中被调用的与主动调用的函数能被明显区分,建一两个文件夹也好,统一为tick、load也好主动与被动取决于该函数是否打算被其它模块,或者是玩家调用主动与被动
相对于模块而言,主动函数就是tick,load以及仅被其调用的一系列本模块函数,相当于运行主体,被动则是属于该模块却被自身或其它模块调用的函数相对于玩家而言,主动函数与被动函数的意义差不多相反,用于被玩家调用的功能函数反而是主动函数,模块自动运行的函数反而是被动函数这里采用相对于模块的视角如果采用系统模块的方式,应该把所有的主动函数都放进系统模块内,系统模块内将会成为一个庞大的编辑区域,此时的系统模块和其它编程语言的main别无二致留下系统模块可以更精准地控制数据包内函数的运行顺序,Xiao2更倾向于留下main模块重点是保持一个贯穿始终的布置规则这里有几个简单的规则1.data/<自己的命名空间>/functions/<数据包空间>/...如果这样的话,s3.chessboard就是data/s3/functions/chessboard/tick.mcfunction对应s3:chessboard/tick这样的好处是自己的不同数据包放在一起的时候翻文件夹会快乐一些2.对于函数<path>/a调用的函数,如果仅它自身调用这个函数,那么就<path>/a/<待调用函数>,这样会使函数调用关系显得一目了然如果<path>/a调用的是一系列相似的函数,则可以直接建一列文件夹,运行<文件夹i>/run3.如果有一堆模块,那么请把调用模块的函数放在显眼一点的地方,这样好在修改模块的时候修改对应的调用例如模块A,B,C有触发函数a,b,c,d那么新建一个空模块0与ABC并列,里面在同样位置放置函数a,b,c,d,但在里面调用ABC的a,b,c,d这是函数标签的替代,如果你是做前置的话当我没说4.计分板可以理解为数据类型,你可以设置int,bool,byte,tmp,float,result等计分板,而用假名区分它们放心大胆用不带命名空间的假名,只要不和自己冲突,写得舒服就行,硬要加命名空间可以加在计分项上面对于临时变量,建议采用不容易重复的函数路径名的一部分作为假名或路径,这样可以在降低记忆负担的同时减少bug但如果非常确信从创建到使用结束中间都没有其它函数插入的话,放心大胆地用类似# tmp,x tmp这种临时变量吧5.对于nbt路径,则可以用命名空间理解为数据类型,我经常采用temp辨别方式取决于它们的更新周期,temp是每tick随时有可能更新的东西,而init只在load时会出现变化,sys用来存储设置和状态一类的东西,也有可能随时变化6.状态这一概念是模块的属性,存在于模块的调用入口处,通过状态决定调用哪一个函数或者采用什么方案例如主函数可以有一个状态"stop",存在于主函数的tick函数,若为1则不调用后续的函数()可以采用计分板sys.stop state,也可以存在storage sys stop内使用这个东西可以把根据条件->调用不同函数变成根据条件->调整状态->调用同一个函数->根据状态调用不同函数这样,,有利有弊吧顺便玩家的潜行,疾跑,坐标,这一类也可以作为状态来理解可以存在玩家的计分板或者个人nbt空间里也可以存在player.xx state里,,毕竟是单tick内数据包才用得到的东西,在as@a的主函数里统一获取和使用就行了
#调试与控制 理想的情况应该是能随时暂停模块或数据包的运行而保持func的可调用所以用主函数的stop状态就行了只是进度要禁的话会麻烦一点点,但一般不禁也没关系吧,,
#命名与注释
旧贴 ##路径与<@s> 为了最大限度地避免重名,数据包使用的计分板和storage空间可以按照路径命名,以可以同时在文件夹,计分板以及storage内使用为标准例如s3_lib/functions/data/set_pointer.mcfunction的计分板名可以设置为s3_lib.data.set_pointer.success [计分板名,storage下的输出存储可以设置为storage data s3_lib.data.set_pointer{success:1b}路径的缩写规定为<@s>,例如上面的storage路径在注释里可以写成scb <@s>. successstorage data <@s>.success
##临时变量 data可以存在storage temp “<@s>”.变量名里,注意这里为了节省性能加上了引号以减少存储的级数,关于storage命名空间的使用见下(#data storage命名空间的使用)scb可以存在scb ##<@s>.变量名[类型]里,注意这里用了两个#,这设定作为临时变量的特有标志
##函数开头注释 函数的开头(系统函数除外)最好都标明输入、输出、运行环境以及函数的作用,没有可以留空可以在模块的__init内重新标明这个模块的路径为一个清爽点的样子(<@s> = xxx),不过注意重名 ( 由于写命名空间这样的东西很不爽所以在确定不会重名的情况下建议省略 )( 划掉 )
见 #最大化编辑维护体验
函数开头注释的话,第一行写这个函数干嘛的,第二行起写输入和输出用人能看得懂的语言写就行,注意输入包括执行位置和执行者,上一级不明的话可以写一下是哪个函数调用的它,以便查bug时方便些(前置函数就算了)主要的函数上写就行了
# data storage命名空间的使用规范建议
见 #最大化编辑维护体验:5. ##temp
- 每tick清空的命名空间,由于并不能确定数据包每tick的运行顺序,所以这里面存储任何值都得是临时性的
-
存储函数的临时变量,以及函数参数(输入)
- 这个命名空间下的值被定义为就算全部删光都不会对数据包的运行造成任何影响的值,比较适合存储命令的返回值
-
存储函数的返回值
- 在数据包加载时就应该确定并且在后续运行中不会再更改的值
-
大部分初始化的值
- 系统运行所依靠的参数,如果init中存在同路径的值,优先级应该高于init
-
用来存储各种设置,以及其它重要的数据
#data和scb的数据储存和利用 首先比较一下两种方式 ##支持类型
- data block/entity 带物品tag:全部
- data storage: 全部
-
scb:仅支持整数存储
- data能一次对大量的数据进行查询,复制,删除
-
scb 一次只能对一个数据进行查询,复制,删除,运算
以下是拿着不同的物品对应运行的函数,所有的存取量都是一样的(上图的21x100次)
我将从后面的格子滚动到前面的格子准备的工作为世界为虚空超平坦世界同时存在的实体数量为331,通过命令方块反复召唤药水云达到,这里不写了/summon minecraft:armor_stand ~~ ~{Tags:["test"]}/data modifyentity4c19e715-29b4-40f5-9cdf-37c6f7a0ba20 HandItems[0] set from entitysch233SelectedItem/setblock 0 3 0minecraft:jukebox/data modify block 0 3 0RecordItem setfrom entity sch233 SelectedItem/data modify storageminecraft:move1 moveset from entity sch233 {}load运行scoreboard players set #0 s3.Int0……………………………………………………scoreboard players set #19s3.Int 19data modify storage test 0 setvalue 0……………………………………………………data modify storage test 19 setvalue 19data modify storage testa.b.c.d.e.f.g.h.0set value 0……………………………………………………data modify storage testa.b.c.d.e.f.g.h.19set value 19data modify storagemove1move.Inventory[{Slot:0b}].tag.0 set value 0……………………………………………………data modify storagemove1move.Inventory[{Slot:0b}].tag.19 set value 19data modify block 0 3 0RecordItem.tag.0set from storage test 0……………………………………………………data modify block 0 3 0RecordItem.tag.19set from storage test 19execute as @e[type=armor_stand,tag=test]runfunction s3_math:main/func_tag/minecraft/load/_ss3_math:main/func_tag/minecraft/load/_s:data modify entity @sHandItems[0].tag.0set from storage test 0…data modify entity @sHandItems[0].tag.19set from storage test 19函数第一行分别以下图片,后续格式和上面的示例一样带@e的data存取
@s data存取
方块data存取
带索引的storage data存取
多级storage data存取
根目录storage data存取
计分板存取
###性能变化 前3个没有明显的区别0,1,2,3不运行,计分板运行,data根目录运行,data多级运行,多级运行的时候开始出现黄线了
3,4,5的区别data多级运行,data索引运行,方块data运行,索引运行的时候开始出现橙色的线,方块data运行的时候开始出现红线方块运行的消耗大概是多级运行的2倍
4,5,6,7的区别,可以看到非常的夸张啊data索引运行,方块data运行,实体@s运行,实体@e运行实体@s运行开始全是红线,是方块运行的两倍,@e运行直接超了一倍多的上限
由于前3个看不出性能,因此将存取量x10后再次测试不运行,计分板运行,data根目录运行,data多级运行,根目录运行消耗大概是scb的2倍,多级运行大概是根目录运行的2倍
把检索改为[0]后的测试(10倍强度),反而比多级测试占用还少,毕竟只有5级(其中一级是[0]),而多级有9级注意这个时候比根目录消耗大不了多少,看起来[0]和普通索引差不多的样子
我们把[0]改为move.Inventory2[0][0][0][0][0][0][0]试试
[0]的引用和直接的引用消耗是一样的好家伙,消耗表出来了(20tps=40消耗,拿尺子量的,图之间的比例差的有点大,取了近似,仅供参考)scb:1.1data{1级}:3.6data{5级}:5data{9级}:8.4data{5级其中一级索引}:10block:17.4@s数据存取:40
@e数据存取:113
@e在不进行对实体的数据存储且全世界实体数量不多的时候性能消耗十分低
data的存储能力很强(支持各种类型),有清晰的存储结构,找东西很方便,能进行较为方便的读取和编辑操作但是卡,即使是根目录的data读取,消耗的时间也是scb的两倍以上,不建议在tick中常调用data的数据(比data更卡的是实体,卡顿随着数量增长而且固定有一定的层级)scb性能很好,目测性能不受名字长度影响,而且可以进行各种数字计算(data不行),结构简单而且有长度限制,假名设定后很难找到,仅支持整数存储建议直接把data当成硬盘操作,scb当成内存操作,每次load都把data转化为计分板(划掉)建议直接把data当成堆操作,scb当成栈操作,除了引用很麻烦之外一切都好(划掉)
#nbt与predicate的性能区别 做这个完全是出于@Jokey_钥匙 的请求的,这里可以看见predicate比nbt到底快了多少倍,,为了比较的公平性,我们所有的predicate判断都采用泥土采用的循环次数和上一节一样,并且统一采用@s
这里把两种nbt判断都用上了并且为了得到更纯粹的性能比较,直接复制粘贴了2100个第一张图是按照与上面一样的方式测试的
右边就和上一节的@s的结果差不多,而用predicate简直和data storage没几级一样(还是比计分板慢的)
## 这里谈一谈我的理解 ( 警告:以下的图和补码的实际运算方式没有任何关系,仅为我个人理解! )
采用补码的优势是所有的减法都可以转化成加法在结果不溢出-2147483648~2147483647的情况下在0~2147483647内,加法可以看作是两个补码直接相加在-2147483648~-1内,加法也可以看作两个补码直接相加两个数分别在两边时,加法还是可以看作是两个补码直接相加多余的1会溢出一位而舍掉,得到的结果是正确的
##int当成unsignedint 可以看到补码从-2147483648~-1,去掉符号位与0~2147483647是一样的事实上绕一圈回来和unsigned int的存储是一致的这意味着,int完全可以当成unsignedint来使用,加法方面不成问题
##改变符号位 如果把任意scb加上-2147483648(也就是仅改变符号位) ,0和±2147483648的意义会对调,负数对调后的值就是负数-(-2147483648)的值,正数对调后的值就是正数-(2147483648)的值-2147483648---------负数---------0----------正数--------------2147483648通过这种办法可以得到到底溢出了2147483647或者-2147483648多少值
#数据类型判断与筛选
##废话 我在第五版数据包设计的可以让玩家用一条命令输入多个函数参数并运行的东东,可以确定的有as,at,positioned,rotated,return(tellraw返回值)的对象以及任意数量的参数,甚至能一条命令运行多个函数,只要你聊天栏装得下但是做这个的过程中遇到了问题:怎么判断玩家输入参数是不是符合函数运行需求的呢?要知道玩家的输入是最无法预料的,而且你也不会知道自己的函数在各种乱七八糟的输入下会有什么反应,因此判断并筛选数据类型势在必行我经过反复尝试和各种灵光一闪,最终找到了以下的判断和筛选方法
##data允许的所有类型 参考 这里
##{}和[]类的类型 使用
- execute store success xxx run data get xx{}
-
execute store success xxx run data get xx[]
##所有数字和字符串
可以利用数组下所有元素必须类型一致的特性
先给每种元素创立一个数组
data merge storage type set value{byte:[1b],int:[1],short:[1s],long:[1L],float:[1.0f],double:[1.0d],str:["1"]}
然后要判断的时候复制对应的类型的数组到storagetemp,
再store successxx run data modify xx.<type> append from 你要判断的值
就行了
##两种字符串的判别 指""型和'{"text":""}'型的字符串的判别,我在这里简称为str和str+它们同时存在于一个数组中是不会报错的 那我们就只能通过方块或实体来判定了 更改告示牌的内容为storage内容的显示 不加上 interpret,str会正确显示而str+不会,
它们在告示牌上存储的内容都改变了,
str的形式会转变为str+的形式,
str+则会在里面加一堆反斜杠,
用data复制回去都会返回成功所以不能用于辨别
更改告示牌的内容为storage内容的显示 加上 interpret,str+会正确显示而str不会,str的的在告示牌上的存储为空,用data复制回去会返回成功,str+在告示牌上的存储不变,用data复制回去会返回错误所以可以采用第二种方法来进行判别,届时比对是否发生了改变即可 以上方法在以str+作为存储方式的实体和方块上应该都有效
#游戏更新顺序
##load 众所周知在load的时候是检测不到玩家的,那么在世界开始加载到玩家进入这段时间到底运行了几次tick或schedule呢
采用添加数据进data的方式,我们可以看看加载顺序是什么样子的
tick,load
tick_schedule,load_schedule,tick
load_schedule,tick_schedule,tick
load_schedule,tick_schedule,玩家进入(,tick...)
看起来gametick是在tick后schedule前刷新的,, ##tick ##直接上图 打算测试的触发方式有tick,advancements,循环型命令方块(RCB),schedule,以及玩家触发的指令所有的指令都是以玩家的计分板不是233为前提条件运行的直接运行,能够得到大概的运行顺序
改一改输出,让它们能输出玩家的坐标
然后飞到万米高空掉下
tick得到y=9530.198schedule得到y=9530.198RCB得到y=9530.198advance 得到y=9530.198玩家执行命令现在我们基本上可以确定顺序了,玩家执行命令和游戏更新的顺序不清楚似乎并没有啥影响 ? 我觉得可以测出来再改进一下
发射器丢物品
结果: tick->schedule->发射器 丢东西出现Age ->RCB->advancement-> (玩家命令->玩家坐标更新)(实体Age更新->玩家丢出的物品出现Age) 然后又测了一个,测试的方式是按钮加中继器配合两个命令方块改计分板控制开启检测并输出到data,懒得截图了,把结果放出来吧
【gametick更新】schedule更新【发射器更新,红石中继器导致的命令方块更新】rcb更新【玩家按按钮导致的命令方块更新】advance更新玩家命令执行【药水云Age更新,玩家坐标更新,玩家丢物品更新】tick更新【下一个gametick更新...】
#杂项
##性能与体验 所有tick触发的函数的运行以性能为优先,尽可能使用计分板传参(见下的#data和scb的数据储存和利用);玩家主动触发的函数一切以使用体验为优先,如果data方便就data来(因为玩家主动触发的通常不会太影响性能),给玩家调整参数和值的东西以data为优先(因为方便找和查看),必要的话可以搞专门的函数来显示和操作
##marker设置 所有类型的marker,不管是药水云盔甲架物品展示框还是为了处理数据包放置的其它什么实体都好,统一加上Marker的tag以防止在kill的时候误杀
# 各种存储或判断方式的性能测试